PixelSphere: Motor de Ingesta Masiva y Streaming de Alta Disponibilidad
AI Powered
Publicado hace 1 mes
•
111 vistas
Node.js
TypeScript
Next.js
Tailwind CSS
Streams API
Crypto
Genkit AI
JSON Storage
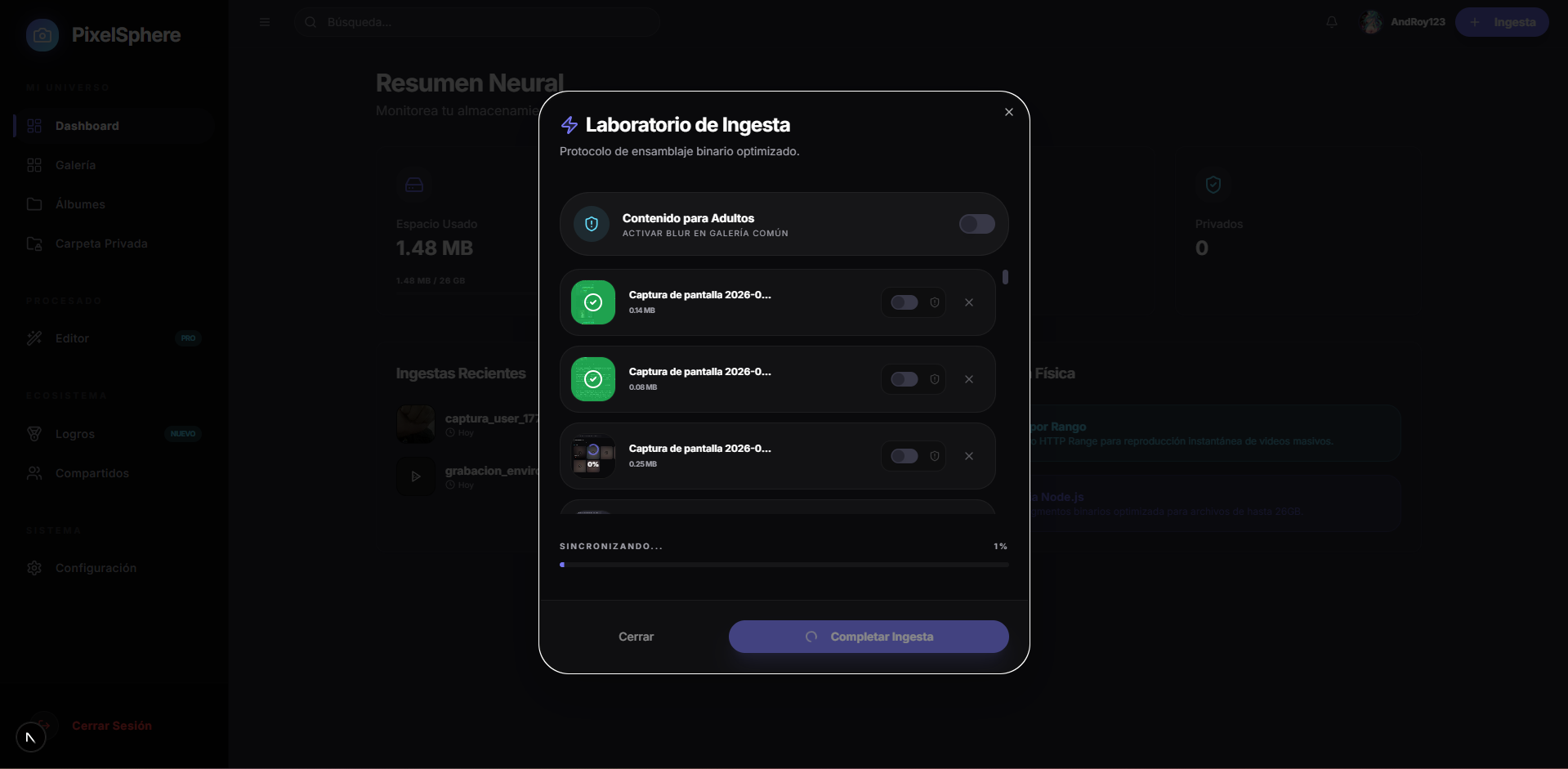
Ingeniería de Carga Masiva y Concurrente
PixelSphere nació como un reto técnico: ¿Cómo gestionar Terabytes de datos y archivos de hasta 26GB sin que el servidor colapse por falta de RAM? La respuesta fue construir un ecosistema basado 100% en el manejo de flujos de datos (Streams) y protocolos de fragmentación.
🧠 Arquitectura del Motor (Deep Dive)
A diferencia de las arquitecturas tradicionales que cargan archivos en memoria antes de procesarlos, PixelSphere utiliza un Protocolo de Ensamblaje Binario:
- Frontend (Chunking): Los archivos se fragmentan en el navegador usando
Blob.slice()en bloques de 10MB. Esto permite que el usuario suba archivos masivos sin congelar la pestaña del navegador. - Backend (Write Streams): Node.js recibe cada fragmento y lo inyecta directamente al disco duro mediante
fs.createWriteStream. Esto garantiza un consumo de RAM constante de solo 10MB, sin importar si el video pesa 100MB o 20GB. - Concurrencia Aislada: El sistema genera un
fileIDúnico por subida, permitiendo múltiples flujos independientes sin colisiones de datos.
📸 Motores de Medios e IA
- Motor de Imagen: Implementa un flujo híbrido. Para imágenes ligeras, utiliza operaciones atómicas en Node.js; para archivos de alta densidad, aplica subidas fragmentadas para asegurar la integridad binaria.
- Motor de Video: Soporta Streaming por Rango (HTTP Range), lo que permite al usuario saltar a cualquier punto del video instantáneamente sin haberlo descargado por completo. Además, genera thumbnails dinámicos mediante técnicas de Client-Side Seeking.
🔒 Persistencia y Seguridad Pro
- Base de Datos Desacoplada: El sistema utiliza archivos JSON Maestros gestionados por el módulo
fsnativo, garantizando atomicidad en las escrituras y facilidad de backup mediante empaquetado dinámico en ZIP. - Cifrado de Bóveda: Los datos sensibles se protegen mediante el algoritmo PBKDF2 con 100,000 iteraciones y salting único de 16 bytes generado vía
randomBytes. - Seguridad de Acceso: Integración de 2FA (TOTP RFC 6238) y biometría nativa vía WebAuthn, elevando el estándar de identidad del proyecto.
Nota Técnica: Este proyecto demuestra que con Node.js puro y una arquitectura bien diseñada, es posible gestionar volúmenes de datos empresariales de forma eficiente y segura sin depender de bases de datos externas pesadas para un prototipado rápido.